
1
COMPUTER VISION
Posted by SUYOG PATIL
on
6:28 PM
in
COMPUTER VISION,
CV,
Image Processing,
matlab,
matlab tutorial,
robotics
Guys,
You must be thinking that we are doing image processing in Matlab which is having vary vast applications but its heavy software......
My advice for beginners in Image Processing(IP) or Computer Vision(CV) will be to apply some algorithms of IP in Matlab first, get hands on it and then start with other language from basic.The other language which I am talking about is none other than your favorite and the most basic language "C" .Ya...its C programming ....
So from now on I will be writing tutorial of IP in C.but before that i want to share some basics of IP/CV so that when you start in C it will be easy for you to understand and to write code.
Go through some very useful and interesting concepts of COMPUTER VISION as they are very important in coding and algorithm point of view...
Image Collection
The very first step would be to capture an image. A camera captures data as a stream of information, reading from a single light receptor at a time and storing each complete 'scan' as one single file. Different cameras can work differently, so check the manual on how it sends out image data.
The very first step would be to capture an image. A camera captures data as a stream of information, reading from a single light receptor at a time and storing each complete 'scan' as one single file. Different cameras can work differently, so check the manual on how it sends out image data.
There are two main types of cameras, CCD and CMOS.

A CCD transports the charge across the chip and reads it at one corner of the array.
An analog-to-digital converter (ADC) then turns each pixel's value into a digital value by
measuring the amount of charge at each photosite and converting that measurement to binary form.
CMOS devices use several transistors at each pixel to amplify and move the charge using more
traditional wires. The CMOS signal is digital, so it needs no ADC.
CCD sensors create high-quality, low-noise images. CMOS sensors are generally more susceptible to noise.
Because each pixel on a CMOS sensor has several transistors located next to it, the light sensitivity of a
CMOS chip is lower. Many of the photons hit the transistors instead of the photodiode.
CMOS sensors traditionally consume little power. CCDs, on the other hand, use a process that consumes lots
of power. CCDs consume as much as 100 times more power than an equivalent CMOS sensor.
CCD sensors have been mass produced for a longer period of time, so they are more mature. They tend
to have higher quality pixels, and more of them. Below is how colored pixels are arranged on a CCD chip:

When storing or processing an image, make sure the image is uncompressed - meaning don't
use JPG's . . . BMP's, GIF's, and PNG's are often (although not always) uncompressed. If you decide
to transmit an image as compressed data (for faster transmission speed), you will have to uncompress
the image before processing. This is important with how the file is understood . . .
Pixels and Resolution
In every image you have pixels. These are the tiny little dots of color you see on your screen, and the smallest possible size any image can get. When an image is stored, the image file contains information on every single pixel in that image.
This information includes two things: color, and pixel location.
Images also have a set number of pixels per size of the image, known as resolution.
You might see terms such as dpi (dots per square inch), meaning the number of pixels you
will see in a square inch of the image. A higher resolution means there are more pixels
in a set area, resulting in a higher quality image. The disadvantage of higher resolution
is that it requires more processing power to analyze an image. When programming
computer vision into a robot, use low resolution.
The Matrix (the math kind)
Images are stored in 2D matrices, which represent the locations of all pixels. All images have an X component, and a Y component. At each point, a color value is stored. If the image is black and white (binary), either a 1 or a 0 will be stored at each location. If the color is greyscale, it will store a range of values. If it is a color image (RBG), it will store sets of values. Obviously, the less color involved, the faster the image can be processed. For many applications, binary images can acheive most of what you want.
Here is a matrix example of a binary image of a triangle:
0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 1 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0It has a resolution of 7 x 5, with a single bit stored in each location. Memory required is therefore 7 x 5 x 1 = 35 bits.
Here is a matrix example of a greyscale (8 bit) image of a triangle:
0 0 55 255 55 0 0 0 55 255 55 255 55 0 55 255 55 55 55 255 55 255 255 255 255 255 255 255 55 55 55 55 55 55 55 0 0 0 0 0 0 0It has a resolution of 7 x 6, with 8 bits stored in each location. Memory required is therefore 7 x 6 x 8 = 336 bits.
As you can see, increasing resolution and information per pixel can significantly slow down your image processing speed.
After converting color data to generate greyscale, Mona Lisa looks like this:

Decreasing Resolution
The very first operation I will show you is how to decrease the resolution of an image. The basic concept in decreasing resolution is that you are selectively deleting data from the image. There are several ways you can do this:
The first method is just delete 1 pixel out of every group of pixels in both X
and Y directions of the matrix.
For example, using our greyscale image of a triangle above, and deleting one
out of every two pixels in the X direction, we would get:
0 55 55 0 0 255 255 0 55 55 55 55 255 255 255 255 55 55 55 55 0 0 0 0and continuing with the Y direction:
0 55 55 0 55 55 55 55 55 55 55 55and will result in a 4 x 3 matrix, for memory usage of 96 bits.
Another way of decreasing resolution would be to choose a pixel, average the values of all surrounding pixels, store that value in the choosen pixel location, then delete all the surrounding pixels.
For example,
13 112 112 13 145 166 166 145 103 103 103 103Using the latter method for resolution reduction, this is what Mona Lisa would look like (below). You can see how pixels are averaged along the edges of her hair.

Thresholding and Heuristics
While the above method reduces image file size by resolution reduction, thresholding reduces file size by reducing color data in each pixel.
To do this, you first need to analyze your image by using a method called heuristics.
Heuristics is when you statistically look at an image as a whole, such as determining the overall
brightness of an image, or counting the total number of pixels that contain a certain color.
For an example histogram, here is my sample
greyscale pixel histogram of Mona Lisa,
and sample histogram generation code.
An example image heuristic plotting pixel count (Y-axis) versus pixel color intensity (0 to 255, X-axis):
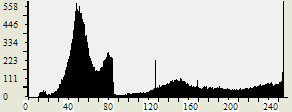
Often heuristics is used for improving image contrast. The image is analyzed, and then bright
pixels is made brighter, and dark pixels is made darker. Im not going to go into contrast details here
as it is a little complicated, but this is what an improved contrast of Mona Lisa would look like
(before and after):


In this particular thresholding example, we will convert all colors to binary. How do you decide
which pixel is a 1 and which is a 0? The first thing you do is determine a threshold -
all pixel values above the threshold becomes a 1, and all below becomes a 0. Your threshold
can be chosen arbitrarily, or it can be based on your heuristic analysis.
For example, converting our greyscale triangle to binary, using 40 as our threshold, we will get:
0 0 1 1 1 0 0 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
If the threshold was 100, we would get this better image:
0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 1 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
As you can see, setting a good threshold is very important. In the first example, you cannot
see the triangle, yet in the second you can. Poor thresholds result in poor images.
In the following example, I used heuristics to determine the average pixel value (add all pixels together,
and then divide by the total number of pixels in the image). I then set this average as the threshold.
Setting this threshold for Mona Lisa, we get this binary image:

Note that if the threshold was 1, the entire image would be black. If the threshold was 255,
the entire image would be white. Thresholding really excels when the background colors are very
different from the target colors, as this automatically removes the distracting background from your image.
If your target is the color red, and there is little to no red in the background, your robot can easily
locate any object that is red by simply thresholding the red value of the image.
Image Color Inversion
Color image inversion is a simple equation that inverts the colors of the image. I havnt found any use for this on a robot, but it does however make a good example . . .
The grey scale equation is simply:
- 255 - pixel_value = new_pixel_value
The grey scale triangle then becomes:
255 255 200 0 200 255 255 255 200 0 200 0 200 255 200 0 200 200 200 0 200 0 0 0 0 0 0 0 200 200 200 200 200 200 200 255 255 255 255 255 255 255
An RBG of Mona Lisa becomes:

Brightness (and Darkness)
Increasing brightness is another simple algorithm. All you do is add (or subtract) some arbitrary value to each pixel:
- new_pixel_value = pixel_value + 10
-
if (pixel_value + 10 > 255)
{ new_pixel_value = 255; }
else
{ new_pixel_value = pixel_value + 10; }

The problem with increasing brightness too much is that it will result in whiteout. For example, if your arbitrarily added value was 255, every pixel would be white. It also does not improve a robot's ability to understand an image, so you probably will not find a use for this algorithm directly.
Addendum: 1D, 2D, 3D, 4D
A 1D image can be obtained from use of a 1 pixel sensor, such as a photoresistor. As metioned in part 1 of this vision tutorial, if you put several photoresistors together, you can generate an image matrix.
You can also generate a 2D image matrix by scanning a 1 pixel sensor,
such as with a scanning Sharp IR.
If you use a ranging sensor, you can easily store 3D info into a much more easily
processed 2D matrix.
4D images include time data. They are actually stored as a set of 2D matrix images,
with each pixel containing range data, and a new 2D matrix being stored after every X seconds of time
passing. This makes processing simple, as you can just analyze each 2D matrix seperately,
and then compare images to process change in time. This is just like film of a movie, which is actually
just a set of 2D images changing so fast it appears to be moving. This is also quite similar to how a human processes temporal
information, as we see about 25 images per second - each processed individually.
Actually, biologically, its a bit more complicated than this. Feel free to read
an email I recieved from Mr Bill concerning biological fps.
But for all intents and purposes, 25fps is an appropriate benchmark.

Computer Vision vs Machine Vision
Computer vision and machine vision differ in how images are created and processed. Computer vision is done with everyday real world video and photography. Machine vision is done in oversimplified situations as to significantly increase reliability while decreasing cost of equipment and complexity of algorithms. As such, machine vision is used for robots in factories, while computer vision is more appropriate for robots that operate in human environments. Machine vision is more rudimentary yet more practical, while computer vision relates to AI. There is a lesson in this . . .
Computer vision and machine vision differ in how images are created and processed. Computer vision is done with everyday real world video and photography. Machine vision is done in oversimplified situations as to significantly increase reliability while decreasing cost of equipment and complexity of algorithms. As such, machine vision is used for robots in factories, while computer vision is more appropriate for robots that operate in human environments. Machine vision is more rudimentary yet more practical, while computer vision relates to AI. There is a lesson in this . . .
Edge Detection
Edge detection is a technique to locate the edges of objects in the scene. This can be useful for locating the horizon, the corner of an object, white line following, or for determining the shape of an object. The algorithm is quite simple:
-
sort through the image matrix pixel by pixel
for each pixel, analyze each of the 8 pixels surrounding it
record the value of the darkest pixel, and the lightest pixel
if (darkest_pixel_value - lightest_pixel_value) > threshold)
then rewrite that pixel as 1;
else rewrite that pixel as 0;
Check out the edges on Mona Lisa:

A challenge you may have is choosing a good threshold. This left image
has a threshold thats too low, and the right image has a threshold thats too high.
You will need to run an
image heuristics program
for it to work properly.


You can also do other neat tricks with images, such as thresholding only
a particular color like red.
Shape Detection and Pattern Recognition
Shape detection requires preprogramming in a mathematical representation database of the shapes you wish to detect. For example, suppose you are writing a program that can distinguish between a triangle, a square, and a circle. This is how you would do it:
-
run edge detection to find the border line of each shape
count the number of continuous edges
-
a sharp change in line direction signifies a different line
do this by determining the average vector between adjacent pixels
if four lines, then a square
if one line, then its a circle
by measure angles between lines you can determine more info (rhomboid, equilateral triangle, etc.)

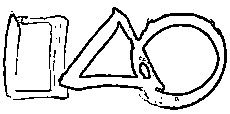
The basic shapes are very easy, but as you get into more complex shapes (pattern recognition) you will have to use probability analysis. For example, suppose your algorithm needed to recognize between 10 different fruits (only by shape) such as an apple, an orange, a pear, a cherry, etc. How would you do it? Well all are circular, but none perfectly circular. And not all apples look the same, either.
By using probability, you can run an analysis that says 'oh, this fruit fits 90% of the characteristics of an apple, but only 60% the characteristics of an orange, so its more likely an apple.' Its the computational version of an 'educated guess.' You could also say 'if this particular feature is present, then it has a 20% higher probability of being an apple.' The feature could be a stem such as on an apple, fuzziness like on a coconut, or spikes like on a pinneapple, etc. This method is known as feature detection.

Middle Mass and Blob Detection
Blob detection is an algorithm used to determine if a group of connecting pixels are related to each other. This is useful for identifying seperate objects in a scene, or counting the number of objects in a scene. Blob detection would be useful for counting people in an airport lobby, or fish passing by a camera. Middle mass would be useful for a baseball catching robot, or a line following robot.
To find a blob, you threshold the image by a specific color as shown below. The blue dot represents
the middle mass, or the average location of all pixels of the selected color.


If there is only one blob in a scene, the middle mass is always located in the center of an object.
But what if there were two or more blobs? This is where it fails, as the middle mass is no longer
located on any object:

To solve for this problem, your algorithm needs to label each blob as separate entities.
To do this, run this algorithm:
-
go through each pixel in the array:
if the pixel is a blob color, label it '1'
otherwise label it 0
go to the next pixel
if it is also a blob color
and if it is adjacent to blob 1
label it '1'
else label it '2' (or more)
repeat until all pixels are done
Above data is taken from my favourite site of robotics(http://www.societyofrobots.com/programming_computer_vision_tutorial.shtml) and i think the best explanation about some basics in COMPUTER VISION.
thank you societyofrobots.com you are doing great job.....
Next session-Getting started in C...
|
